
微博舆情信息老化模型能较好地表示微博舆情信息的老化状况,并有效计算出峰值所在时间,同类型突发事件间峰值发生时间较为接近。
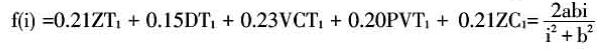
利用实证数据对模型进行一元非线性回归分析,即可求得模型中的参数,进而得到微博舆情信息老化峰值和达到峰值所需的时间。微博舆情信息老化峰值越高,说明舆情事件在微博用户中产生的影响力越高,越能激发微博用户参与到微博舆情的传播和讨论中;而其所需的时间越少,说明舆情事件传播速度越快,微博用户对事件中所包含的内容越敏感。
当f′(x)>0时,微博舆情信息处于加速增长状态,容易滋生不当的网络谣言影响微博舆情的健康发展;当f′(x)<0时,微博舆情信息的增长开始减缓,说明舆情事件的热度正在逐步的衰退,若在此前进行恰当的人为干预,可有效地加快微博舆情信息的老化,也能将舆情引导向更积极的方向。当f′(x)=0,说明此时微博舆情信息正处于单位增量最大,热度最高的时刻,此时的舆情更偏向于非理性,动机不良的人士也容易在此刻散播有害网络社区安定的言论,误导的走向,甚至会将引诱到其他舆情事件中,激化更多舆情事件中的矛盾。
本文以新浪微博作为实证数据来源,选取新闻类微博“云南导游辱客”事件和“西双版纳导游辱客”事件作为实证主题,利用网络爬虫gooseeker爬取对两则事件进行报道的传统新闻媒体微博下的转发与评论作为实证样本。
利用微博高级搜索功能,在输入栏中输入“云南”、“导游”、“良心”等关键词,限定搜索对象类型为“媒体”,评论网时间选择为2015年5月2日0时至2015年5月2日24时,最终筛选出@人民日报、@新京报、@新闻晨报等12家媒体,合计影响覆盖2.8172亿人次。
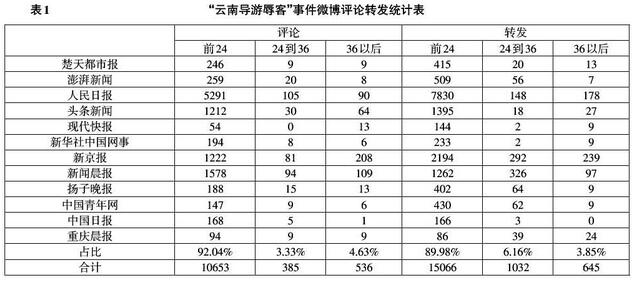
将爬虫所爬取的评论和转发信息按时间顺序进行采集并保存,合计采集评论11828条,转发14729条。利用excel批量抽取每条记录中的发布时间并汇总统计,得到每个媒体微博关于“云南导游辱客”事件报道的全部转发和评论发布时间分布,如表1所示。
同理,对实证二进行数据采集时利用微博的高级搜索将关键词限定为“西双版纳导游”、“一毛不拔”、“铁公鸡”,时间为2016年1月31日0时至2016年1月31日24时,通过搜索和筛选(筛选条件同上一则事件),最终由@南方日报、@新闻晨报、@南方都市报等五家新闻媒体构成本次实证的研究样本,合计影响覆盖8216万人次,合计采集评论1864条,转发1670条。利用excel批量抽取每条记录中的发布时间并汇总统计,得到每个媒体微博关于报道的全部转发和评论发布时间分布,如表2所示。
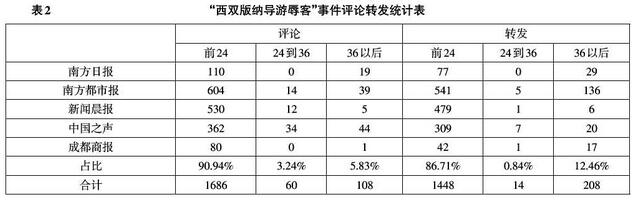
由表1、表2可见,两则事件的评论和转发85%以上都发生在微博发布后24小时内,进一步对事件前24小时的评论和转发进行整理,发现均在第1小时内就达到微博舆情信息单位时间增长量的最大值,随后增长速度迅速回落直至微博近乎“消亡”。



